Parallel Speed up using OpenMP
1. Introduction
> “Why wait for one person to complete a task, when a team can do it together—at the same time?”
In the early days of computing, systems relied on a single processor to handle all tasks sequentially. One CPU was responsible for everything—from handling I/O to executing user applications—step by step.
But with the rise of multi-core processors and technologies like hyper-threading, things have changed. Now, multiple tasks can be executed in parallel, provided they are independent of each other. Each task can be assigned to its own CPU core, enabling better system utilization and faster execution.
On Linux systems, you could use POSIX threads (pthreads) to manually manage concurrency and assign threads to specific cores. However, doing this correctly requires in-depth knowledge of low-level thread management.
This is where OpenMP comes in.
2. What is OpenMP?
Imagine you’re faced with a big task—like sorting through a huge stack of papers. Doing it alone would take forever. But if you call in a few friends, divide the work, and let everyone sort a portion at the same time, the job gets done much faster. That’s essentially what OpenMP does for your code.
OpenMP (Open Multi-Processing) is an API designed for shared-memory parallel programming in C, C++, and Fortran. It allows developers to write parallel code easily by using compiler directives—special annotations that tell the compiler how to divide certain parts of a program into separate tasks that can run simultaneously.
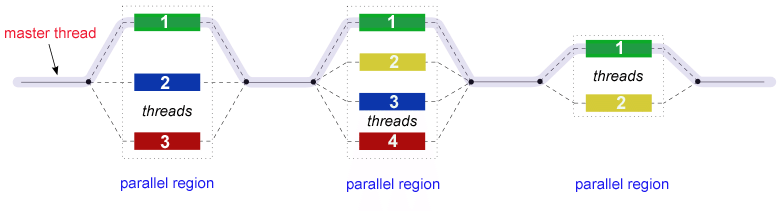
It’s a fork-join model:
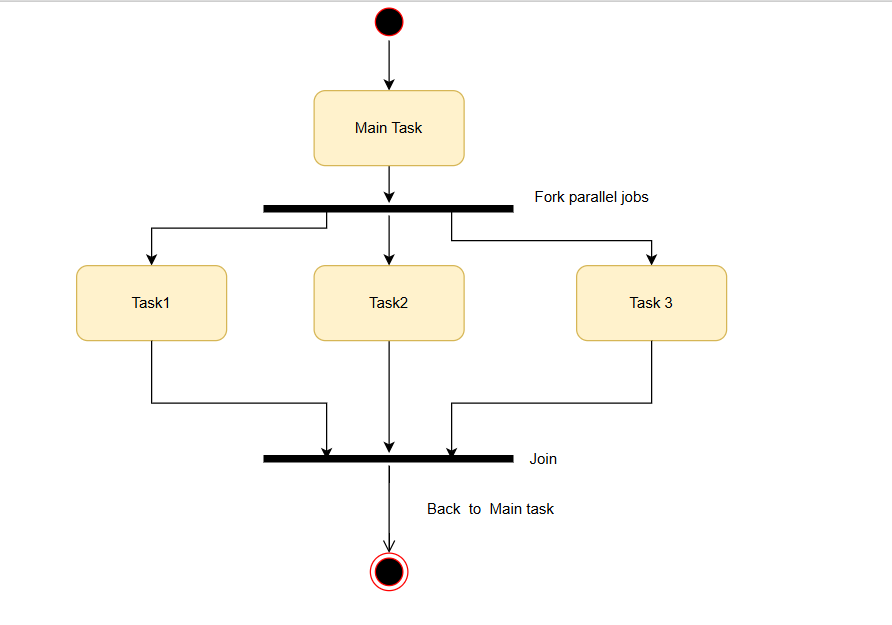
Instead of managing threads manually, OpenMP lets you focus on the logic of your program, while it takes care of splitting the work and distributing it across available CPU cores.
3. How to use OpenMP for parallelism?
In this example, we are going to see the impact of parallelism on performance by comparing the execution time of a heavy loop in a serial way and a loop instructed by #pragma omp parallel for reduction(+:sum_parallel) of GCC.
#include <stdio.h>
#include <stdint.h>
#include <omp.h>
#include <time.h>
#define N 100000000
double time_diff_ms(struct timespec start, struct timespec end) {
return ((end.tv_sec - start.tv_sec) * 1000.0) +
((end.tv_nsec - start.tv_nsec) / 1e6);
}
int main() {
struct timespec start, end;
uint64_t i;
uint64_t sum_serial = 0, sum_parallel = 0;
/* ---------- Serial version ---------- */
clock_gettime(CLOCK_MONOTONIC, &start);
for (i = 0; i < N; i++) {
sum_serial += i;
}
clock_gettime(CLOCK_MONOTONIC, &end);
printf("Serial Sum: %llu\n", sum_serial);
printf("Serial Time: %.3f ms\n", time_diff_ms(start, end));
/* ---------- Parallel version ---------- */
omp_set_num_threads(4); // Adjust this as needed
clock_gettime(CLOCK_MONOTONIC, &start);
#pragma omp parallel for reduction(+:sum_parallel)
for (i = 0; i < N; i++) {
sum_parallel += i;
}
clock_gettime(CLOCK_MONOTONIC, &end);
printf("Parallel Sum: %llu\n", sum_parallel);
printf("Parallel Time: %.3f ms\n", time_diff_ms(start, end));
return 0;
}Compile with:
gcc -fopenmp open_mp.c -o omp_testThis small experiment shows a 3x+ speedup when using OpenMP with 4 threads.
4. Limitation of Parallelism by Design (Serial Bottleneck)
Parallel programming promises faster performance by splitting tasks across multiple threads. However, not all parts of a program can be parallelized, and this is where we hit a fundamental limitation known as the serial bottleneck.
To understand the upper bound of speedup in parallel systems, we refer to Amdahl’s Law:
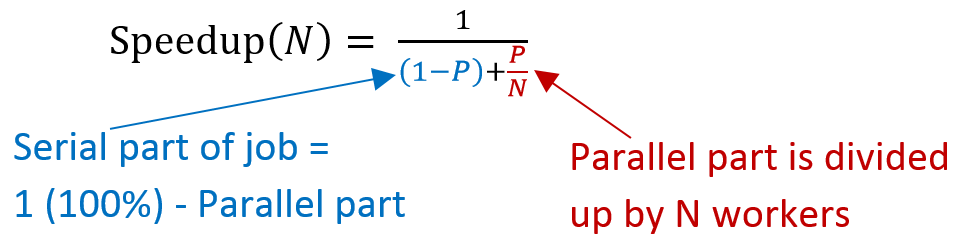
No matter how many cores you throw at a problem, the parts that must run serially become the limiting factor. If only 80% of a program can be parallelized, the maximum speedup—even with infinite cores—is only 5 times.
To demonstrate this limitation, we simulate a fixed serial part (such as an I/O wait) that cannot be parallelized. The rest of the code performs a simple parallel computation using OpenMP.
#include <stdio.h>
#include <stdint.h>
#include <omp.h>
#include <time.h>
#include <unistd.h>
#define N 100000000
#define IO_WAIT_TIME 1 /*1 s*/
double time_diff_ms(struct timespec start, struct timespec end) {
return ((end.tv_sec - start.tv_sec) * 1000.0) +
((end.tv_nsec - start.tv_nsec) / 1e6);
}
int main() {
struct timespec start, end;
uint64_t i;
uint64_t sum_parallel = 0;
for (int threads = 1; threads <= 8; threads *= 2) {
omp_set_num_threads(threads);
sum_parallel = 0;
clock_gettime(CLOCK_MONOTONIC, &start);
/* Simulate io block time */
sleep(IO_WAIT_TIME);
/* Parallel computation */
#pragma omp parallel for reduction(+:sum_parallel)
for (i = 0; i < N; i++) {
sum_parallel += i;
}
clock_gettime(CLOCK_MONOTONIC, &end);
printf("Threads: %d | Total Time: %.3f ms | Sum: %llu\n",
threads, time_diff_ms(start, end), sum_parallel);
}
return 0;
}Even as we increase the number of threads (1 → 8), this has no effect on the overall execution time:

5. How to Mitigate Serial Bottlenecks
Even though parallel programming can significantly speed up computations, serial bottlenecks often set a hard limit on how much performance you can actually gain. To work around this, the best approach is to reduce the amount of code that must run serially. One way to do this is by carefully analyzing your program’s flow and finding opportunities to break tasks into independent parts that can be run in parallel.
For example, if there’s an I/O operation that blocks everything else, try to move that I/O outside the critical performance path or overlap it with computation. Additionally, it helps to adopt parallel-friendly algorithms that naturally scale with threads and avoid unnecessary synchronization between threads, which can slow things down.
Ultimately, improving parallel performance isn’t just about throwing more threads at a problem—it’s about designing smarter code that minimizes sequential bottlenecks wherever possible.
6. Conclusion
OpenMP offers an easy and effective way to introduce parallelism into your programs. While it can deliver significant speedups, true performance gains require understanding and minimizing serial bottlenecks. Use OpenMP wisely and design your code to take full advantage of parallel execution for the best results.