Interrupt Debt and Determinism: FreeRTOS Without the Queue Traffic Jam
Introduction
Picture a motor-control board on a load bench. Every 250 microseconds, a DMA interrupt drops 128 bytes of current and voltage samples in RAM. The spec says the control loop must act within 40 microseconds, but the firmware uses a FreeRTOS queue to move data out of the ISR. When the load spikes, queue send times stretch, the ISR overruns, and the motor audibly chatters. Lab notes from that day were filled with timing scribbles; the bug wasn’t logic, it was the plumbing. The team was paying “interrupt debt” every time the ISR tried to copy into a queue while the scheduler had interrupts masked. The fix was to stop copying altogether.
This article dives into that fix: stitching together FreeRTOS direct-to-task notifications and zero-copy stream buffers so that a firehose of DMA completions never blocks, never copies, and never surprises the schedulability analysis. It’s an advanced pattern, but a surprisingly pragmatic one once the ISR is treated as a publisher of ownership, not bytes.
1. Why Queue-Centric ISRs Collapse Under Burst Traffic
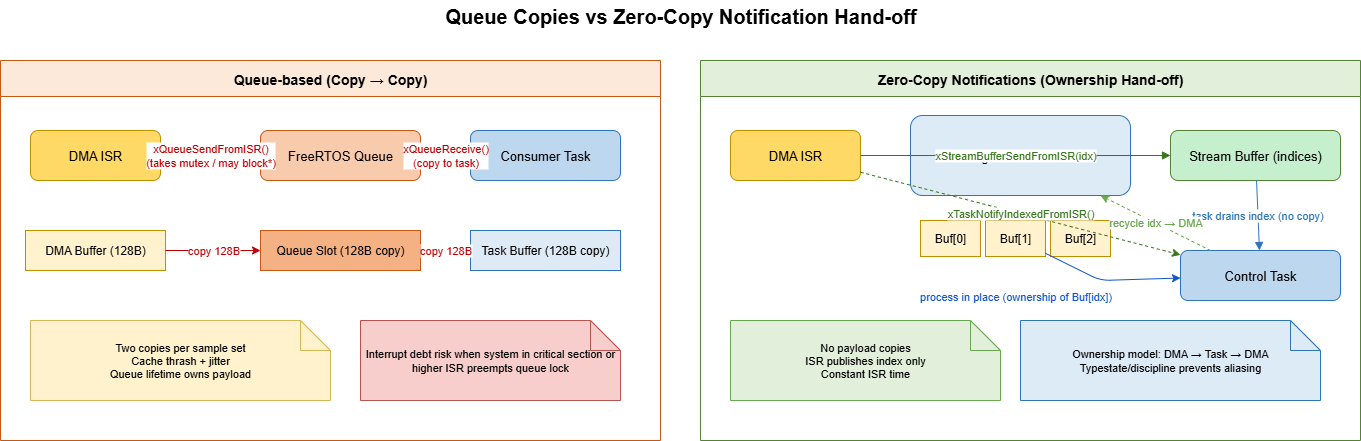
A queue is a beautiful abstraction until an ISR hits it at waveform speeds. Under the hood, xQueueSendFromISR() still has to take the queue mutex, allocate a copy slot, and maybe wake a task. If the system is in a critical section—think taskENTER_CRITICAL_FROM_ISR() nesting or a higher-priority interrupt running—the send spins on a loop that defers the copy. At 250 µs cadence, those deferments pile up as interrupt debt: the ISR keeps returning late, jitter blooms, and eventually configASSERT() fires because uxQueueSpacesAvailable went negative.
Dig through the trace and you see the pattern: the ISR copies 128 bytes, the consumer copies another 128 bytes, and cache lines bounce. That’s 256 bytes of pointless traffic per sample set. Worse, the queue owns the lifetime of the buffer; you can’t reclaim it until the consumer drains the slot. In a burst, the queue sits full of stale data while the DMA is already writing fresh samples into a completely different location.
The insight that saved the project was recognizing that FreeRTOS queues were doing too much: the design needed signaling, not storage. Once those roles were separated, the ISR stopped fighting the scheduler.
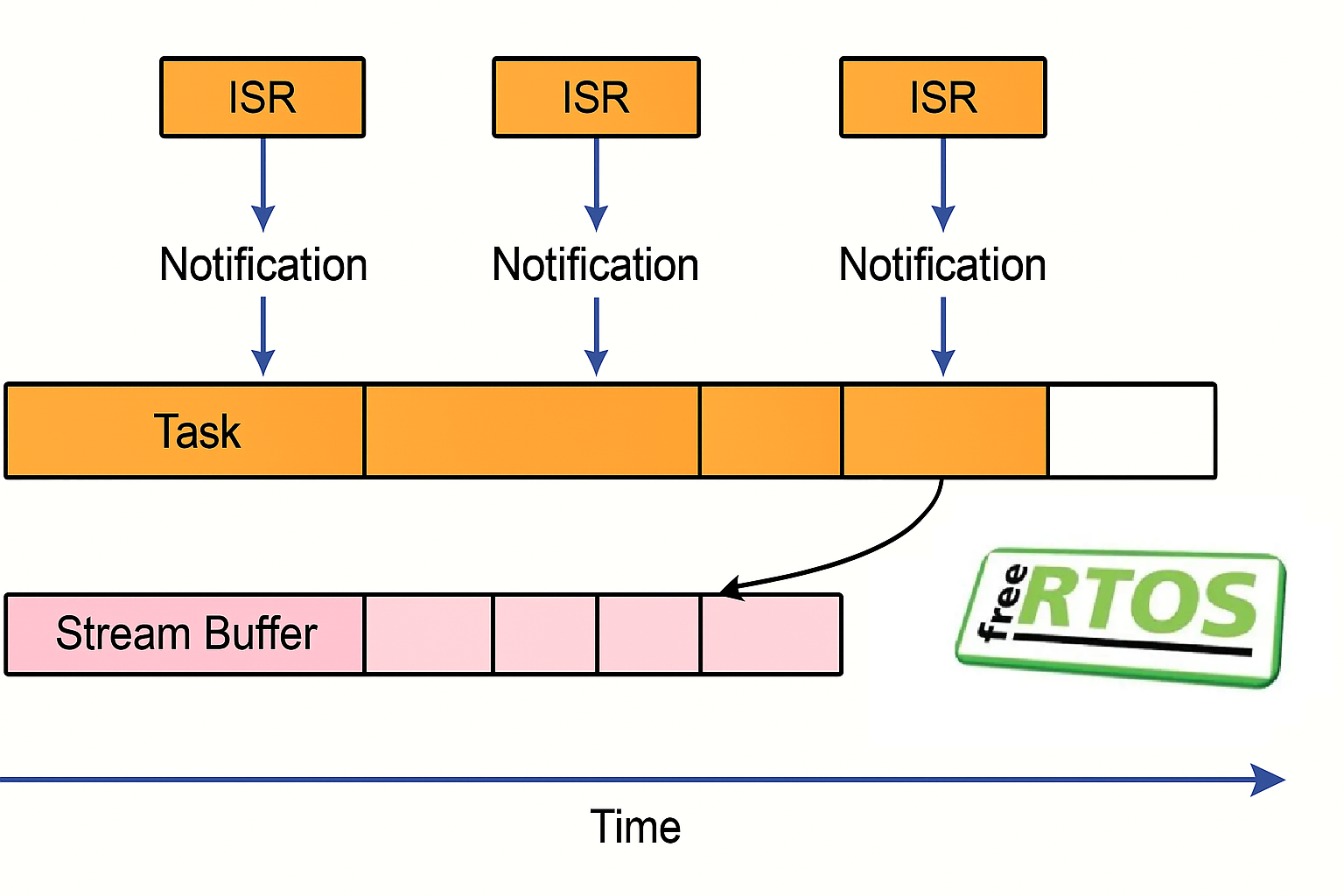
_Figure 1. Splitting signaling from storage eliminates duplicate copies and keeps cache traffic predictable._
2. Building a Zero-Copy DMA Bridge with Direct-to-Task Notifications
FreeRTOS gives us three tools that slot together perfectly: static stream buffers for zero-copy storage, direct-to-task notifications for single-word signaling, and the xTaskNotifyIndexedFromISR() API that can publish bitmasks without touching a queue. The recipe looks like this:
- Pre-allocate a ring of DMA buffers in TCM/AXI SRAM.
- Hand the DMA the next buffer address from the ring.
- When the DMA interrupt fires, push just the buffer index into a stream buffer and poke the control task via a notification.
- Let the control task drain indices, process in place, then recycle the buffer.
#define DMA_DEPTH 4
#define SAMPLE_WORDS 128
static uint16_t dma_storage[DMA_DEPTH][SAMPLE_WORDS] __attribute__((section(".dma_sram")));
static StaticStreamBuffer_t idx_stream_ctrl;
static uint8_t idx_stream_mem[DMA_DEPTH];
static StreamBufferHandle_t idx_stream;
static TaskHandle_t control_task;
void dma_init(void)
{
idx_stream = xStreamBufferCreateStatic(sizeof idx_stream_mem,
1, /* trigger level: deliver every index */
idx_stream_mem,
&idx_stream_ctrl);
control_task = xTaskGetHandle("ctrl");
configASSERT(control_task);
dma_start_transfer(dma_storage[0], SAMPLE_WORDS);
}
void DMA_IRQHandler(void)
{
BaseType_t hpw = pdFALSE;
const uint8_t finished = dma_consume_finish_flag();
xStreamBufferSendFromISR(idx_stream, &finished, sizeof finished, &hpw);
xTaskNotifyIndexedFromISR(control_task,
0,
finished,
eSetValueWithoutOverwrite,
&hpw);
portYIELD_FROM_ISR(hpw);
}
static void control_loop(void *arg)
{
uint32_t last_idx = 0xFFFFFFFFu;
for (;;) {
uint32_t idx;
xTaskNotifyWaitIndexed(0, 0, 0xFFFFFFFFu, &idx, portMAX_DELAY);
if (idx == last_idx) { continue; } // ISR can coalesce notifications
last_idx = idx;
uint16_t *samples = dma_storage[idx];
run_current_loop(samples, SAMPLE_WORDS);
dma_recycle_buffer(idx);
}
}A few details make this sing:
- The stream buffer is byte-sized because only indices are pushed; that keeps the ISR work constant and avoids an
xHigherPriorityTaskWokenstorm. - The notification value doubles as a simple sequence counter, letting the task detect coalescing if the ISR piggybacks multiple completions.
- The buffers live in a linker-script section the DMA and CPU can both access without cache maintenance.
The punchline: the ISR never copies the payload, and the control task never waits on a mutex. Ownership, not bytes, crosses the boundary.
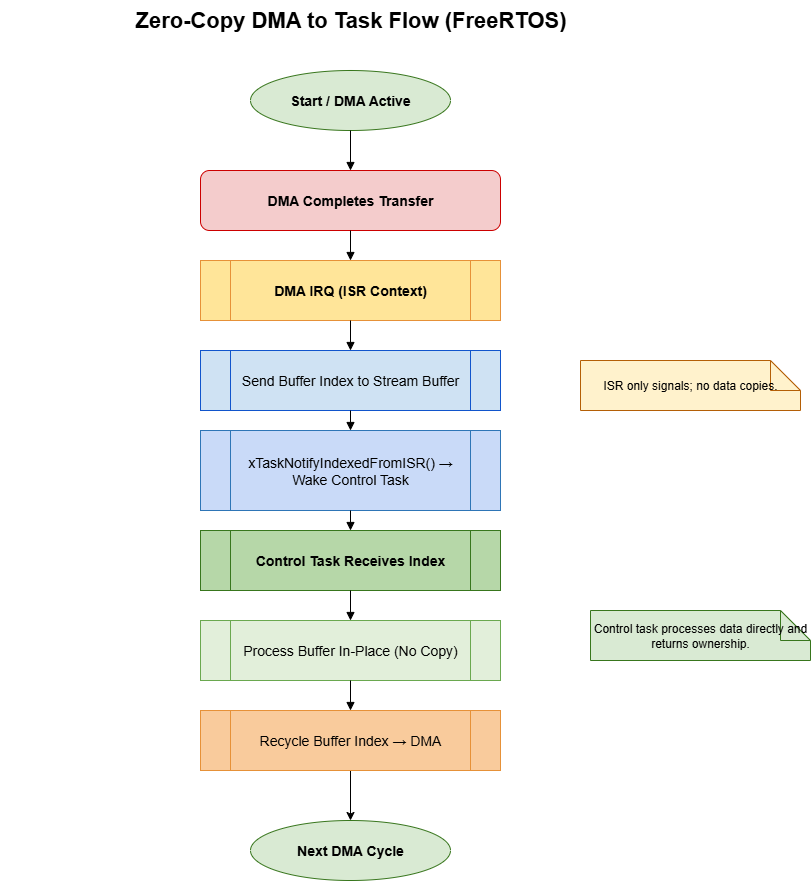
_Figure 2. Stream buffers carry buffer indices while direct notifications prod the control task, leaving samples in place._
3. Scheduling Guarantees Without Priority Surprises
Going zero-copy doesn’t mean the scheduler can be ignored. The system still needs deterministic preemption rules, or one jitter source simply replaces another. Three guardrails keep the pipeline honest:
- Interrupt priority math:
DMA_IRQHandlerruns belowconfigMAX_SYSCALL_INTERRUPT_PRIORITY, so it can callxStreamBufferSendFromISR, but above routine peripheral interrupts that would otherwise delay it. Sketch the priority ladder next to the vector table and hold every ISR that touches a FreeRTOS API to the same rule. - Deferred processing budget: The control task runs at priority
tskIDLE_PRIORITY + 3, comfortably above telemetry/logging tasks but below the watchdog kicker. A quick throughput tally—128 samples × 12-cycle multiply–accumulate per axis—lands near 7 µs on an M7. With context-switch overhead, the worst-case completion stays around 11 µs, well inside the 40 µs budget even during bursts. - Masking discipline: Any code that wraps
taskENTER_CRITICAL()must exit quickly, or notifications pile up. DroppingconfigASSERT(uxInterruptNesting == 0)into debug builds around suspicious sections flushes out routines that run with interrupts masked longer than expected.
With those rules enforced, the “interrupt debt” never materializes. The DMA ISR publishes indices at line rate, the control task budgets the work, and priority inversion stays theoretical instead of a 2 a.m. pager.
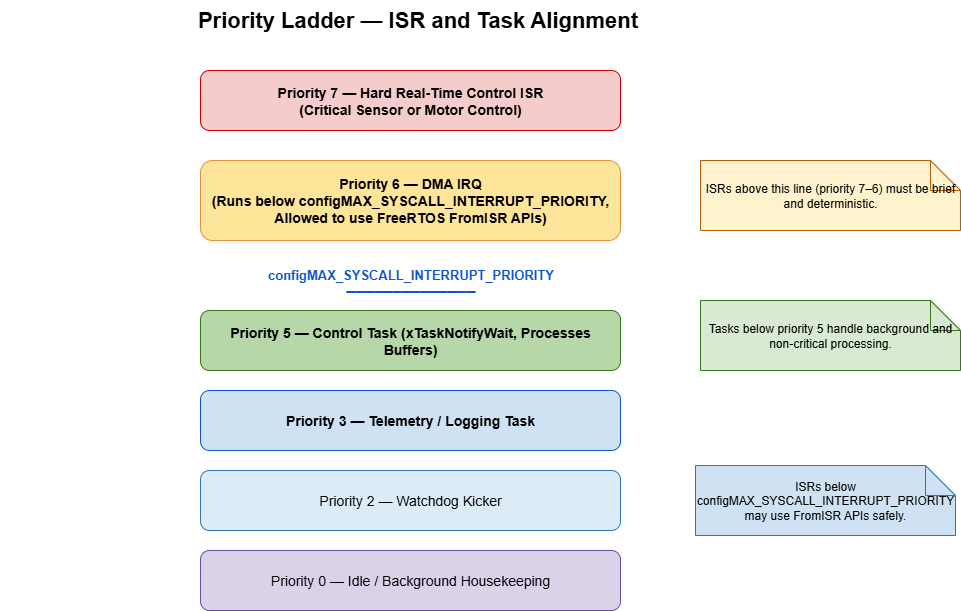
_Figure 3. A strict priority ladder keeps the DMA ISR callable inside FreeRTOS while shielding it from lower-rate peripherals._
4. Proving Latency with Trace Hooks and Backpressure Tests
Guarantees deserve evidence. FreeRTOS trace hooks provide timestamps you can trust. Enable configUSE_TRACE_FACILITY, point the build at Percepio Tracealyzer or SEGGER SystemView, and add two hooks:
void traceTASK_SWITCHED_IN(void)
{
if (pxCurrentTCB == control_task) {
perf_mark(ts_task_start);
}
}
void traceTASK_SWITCHED_OUT(void)
{
if (pxCurrentTCB == control_task) {
perf_measure(ts_task_start, ts_task_stop);
}
}Pair those hooks with xStreamBufferBytesAvailable() sampled by a low-priority telemetry task to keep a live view of headroom. Stress testing means hammering the design with synthetic bursts—shorten the DMA period to 125 µs for two seconds, inject cache invalidate misses by toggling the CPU clock, and watch whether the stream buffer ever fills. If the watermark breaches 75%, the control task is falling behind and either cycles must be shaved or another buffer added to the ring.
Backpressure is deliberate here. When the control task intentionally delays recycling a buffer, the DMA sees a full ring and calls an application hook. That hook toggles a GPIO tied to the oscilloscope. During endurance tests, that GPIO never twitched—a better sleep aid than a thick stack of spreadsheets.
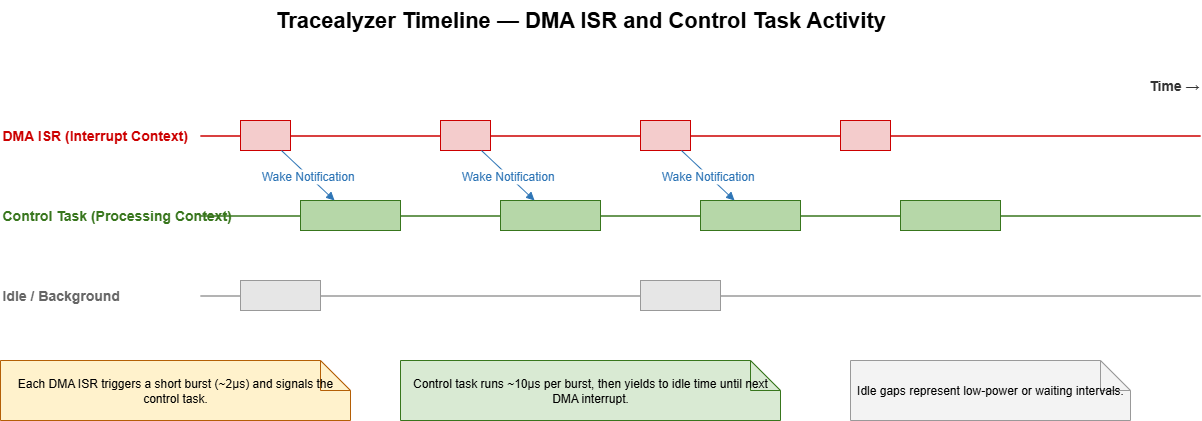
_Figure 4. Trace hooks and saturation tests verify that backlog never builds and latency stays inside budget._
Conclusion
Queues are fantastic until they aren’t. In high-rate interrupt systems, the combination of stream buffers, direct notifications, and ruthless priority discipline lets FreeRTOS behave like a true real-time executive instead of a polite thread library. By making the ISR hand off ownership, not bytes, interrupt debt disappears, the control loop stays deterministic, and instrumentation proves it. The next time a scope trace shows the ISR coming back late, the smarter fix may be a better handoff rather than tighter code.