Producer–Consumer Made Simple: Double Buffering Explained
1. Introduction
The producer–consumer problem is one of the classic problems in computer science. At its core, it deals with balancing the speed of data production against the speed of data consumption. The general rule is simple: the consumer must always be faster than the producer.
But in real systems, that's not always the case.
Take a common embedded scenario: an Ethernet ISR or a DMA controller rapidly writing incoming data into a memory buffer. On the other side, a consumer task in your RTOS reads from that buffer to process the data. If the producer pushes data faster than the consumer can handle, the buffer will overflow — and packets or samples will be lost.
This mismatch between producer and consumer speeds is where things get tricky. To solve it, embedded engineers often turn to a simple but powerful technique: double buffering.
2. What is Double Buffering?
Double buffering is a simple yet powerful concept. Instead of relying on a single buffer that both the producer and the consumer share, the system allocates two buffers that alternate between roles. While the producer, such as a DMA controller or an interrupt service routine, is busy filling one buffer with fresh data, the consumer, typically a task in the RTOS, is working on the other buffer. Once the producer finishes writing, the roles switch, and the process repeats in a continuous cycle.
This "ping-pong" style of operation guarantees that both sides of the system always work on different memory regions. The consumer never encounters a half-written buffer, and the producer never overwrites data that has not yet been processed. The result is a smooth and predictable flow of data with no collisions. In practice, this approach ensures that samples are not lost, that processing occurs in regular blocks of data, and that jitter or unpredictable timing glitches are minimized.
Double buffering is a technique that appears across many domains of embedded systems. In signal processing, it allows ADCs and DACs to stream data continuously without interruption. In graphics, it enables one frame to be displayed while the next frame is being rendered, resulting in smooth animations. In audio systems, it prevents the clicks and gaps that would occur if playback had to wait for data. Even in communication stacks, ping-pong buffers are used to manage the constant flow of packets without dropping them. In short, double buffering is one of the most reliable tools an embedded engineer can use when designing systems that deal with continuous data streams.
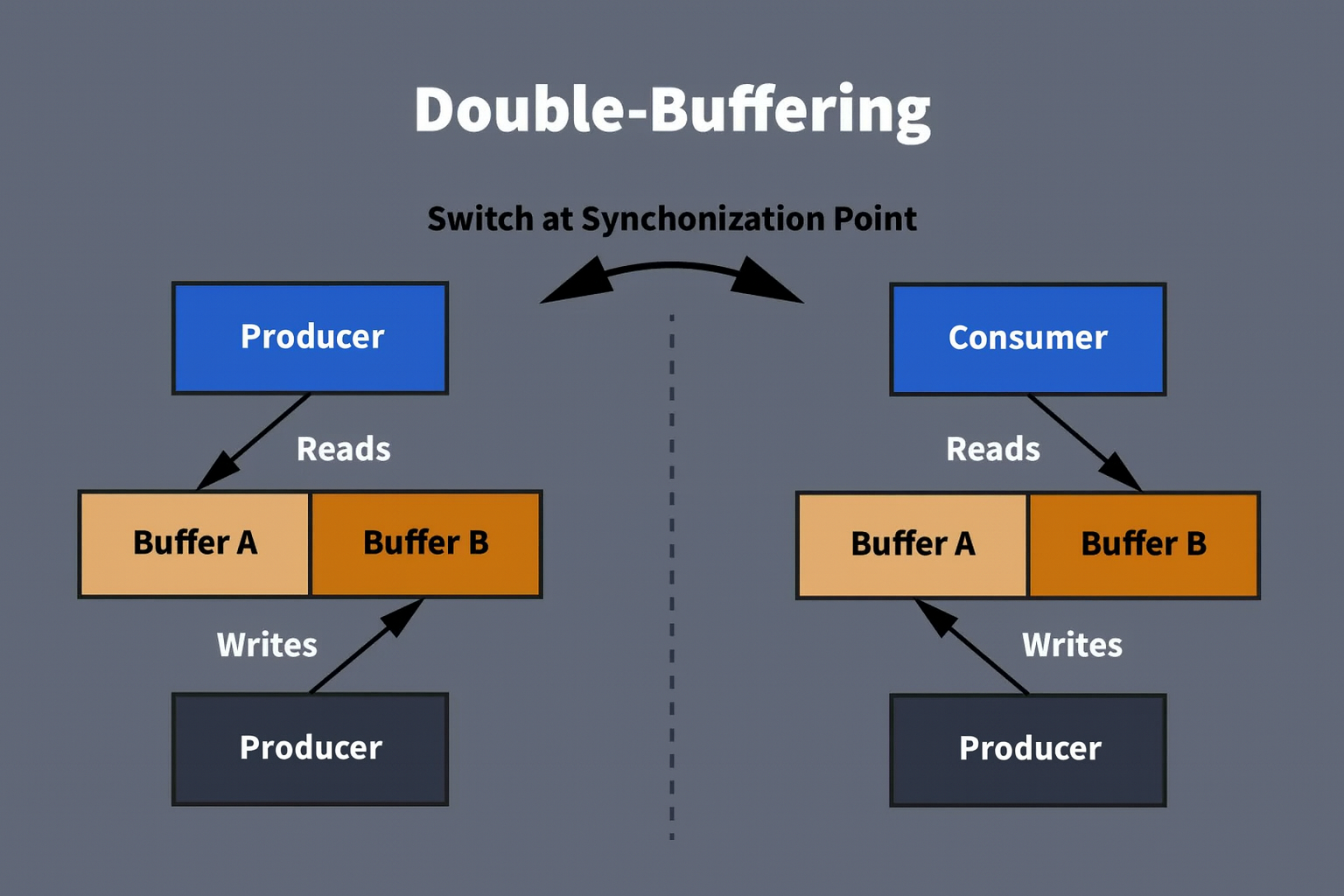
Figure 1 – Double-Buffering technique
3. Practical Example of Double Buffering
One of the most common applications of double buffering in embedded systems is audio processing. Consider an MCU connected to an audio codec through an I²S interface. The incoming audio stream must be captured continuously, so the DMA controller is configured to transfer samples directly from the I²S peripheral into memory. To sustain this flow without gaps, the DMA runs in circular mode and generates interrupts whenever half or all of the buffer has been filled. These interrupts act as synchronization points where the producer, in this case the DMA, hands over ownership of a completed block of samples to the consumer.
On the consumer side, a FreeRTOS task waits until it is signaled that a block is ready. When the half-transfer interrupt fires, the callback indicates that the first half of the buffer, or the "ping" region, is available. The task then performs its processing on that block, such as running an FFT to extract frequency-domain information. Meanwhile, the DMA continues streaming fresh samples into the "pong" region. Once the full-transfer interrupt occurs, the second half of the buffer is complete, ownership is handed over to the task, and processing switches to the pong region. This ping–pong cycle repeats indefinitely, creating a steady pipeline that ensures no data is lost and no CPU cycles are wasted.
What makes this design powerful is that the CPU never blocks waiting for data, and the DMA never overwrites samples before they are consumed. By using FreeRTOS synchronization primitives instead of polling, the system maintains low latency, low jitter, and deterministic behavior. The result is a reliable audio stream that can be processed in real time.
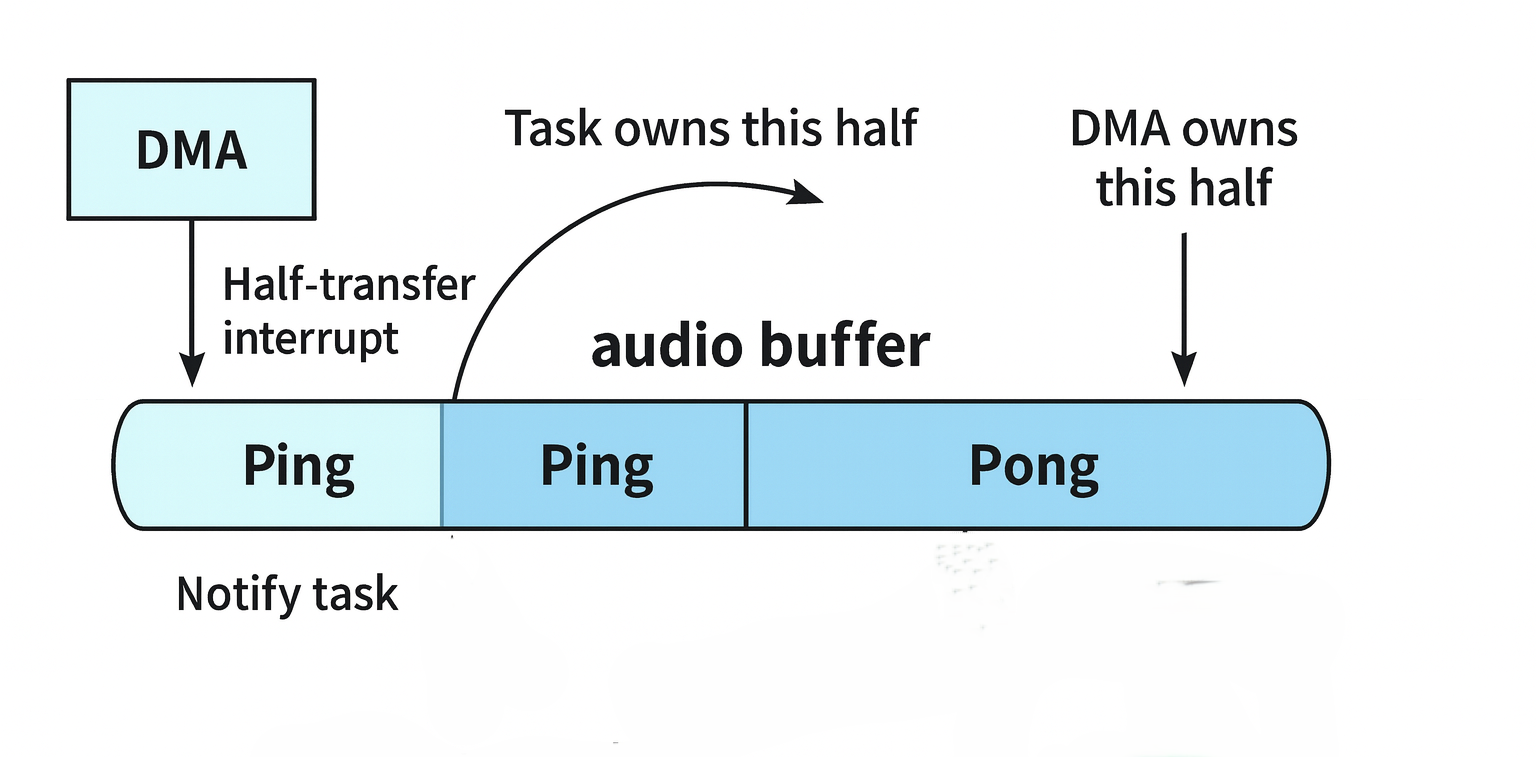
Figure 2 – Double buffering with DMA and FFT task
The pseudocode below illustrates this pattern in practice, using a single buffer divided into two halves and an event group to synchronize ownership between the DMA callbacks and the FFT task:
/** Single DMA buffer split into two halves */
int16_t audio_buffer[BUFFER_SIZE]; /* BUFFER_SIZE = 2 * HALF_SIZE */
/** Event group used for synchronization */
EventGroupHandle_t buffer_event_group;
/** Event bits for ping and pong ownership */
#define PING_READY (1 << 0)
#define PONG_READY (1 << 1)
/** DMA + I2S initialization */
void init_dma_i2s()
{
configure_I2S();
configure_DMA(audio_buffer, BUFFER_SIZE);
start_DMA_I2S(); /* Start continuous circular transfer */
}
/** Callback for half-transfer complete (Ping) */
void DMA_HalfTransfer_Callback() {
/* Signal that the first half (Ping) is ready */
BaseType_t xHigherPriorityTaskWoken = pdFALSE;
xEventGroupSetBitsFromISR(buffer_event_group, PING_READY, &xHigherPriorityTaskWoken);
portYIELD_FROM_ISR(xHigherPriorityTaskWoken);
}
/** Callback for full-transfer complete (Pong) */
void DMA_FullTransfer_Callback() {
/* Signal that the second half (Pong) is ready */
BaseType_t xHigherPriorityTaskWoken = pdFALSE;
xEventGroupSetBitsFromISR(buffer_event_group, PONG_READY, &xHigherPriorityTaskWoken);
portYIELD_FROM_ISR(xHigherPriorityTaskWoken);
}
/** FreeRTOS task that processes audio blocks */
void FFT_Task(void *params)
{
EventBits_t uxBits;
int16_t *current_buffer;
init_dma_i2s();
while (true) {
/** Wait until one of the halves is marked ready */
uxBits = xEventGroupWaitBits(
buffer_event_group,
PING_READY | PONG_READY,
pdTRUE, /* Clear bits on exit */
pdFALSE, /* Wait for any bit */
portMAX_DELAY
);
/** Decide which half belongs to us */
if (uxBits & PING_READY) {
current_buffer = &audio_buffer[0];
}
else if (uxBits & PONG_READY) {
current_buffer = &audio_buffer[BUFFER_SIZE / 2];
}
/** Perform FFT on the chosen half */
process_spectrum(current_buffer);
}
}4. Conclusion
Double buffering is a simple yet powerful technique to bridge the speed gap between producers and consumers in embedded systems. By alternating ownership of two buffer halves, it ensures continuous data flow, minimizes jitter, and prevents data loss. Whether applied to audio streaming, graphics, or communication systems, this method provides a reliable and efficient foundation for real-time processing.