From MCU to Cloud: Lightweight Serialization with Nanopb
1. Introduction:
In modern embedded systems, microcontrollers often need to exchange structured data with PCs, smartphones, or cloud services. This could be telemetry, configuration parameters, or sensor readings. The challenge is that these platforms use different programming languages and environments, while microcontrollers have very limited RAM and flash. To make communication reliable and portable, the raw data must be turned into a structured, machine-independent format — a process known as serialization.
2. What Is Serialization?
Serialization is the process of converting structured data (for example, a sensor reading with timestamp and value) into a portable byte stream that can be sent over a serial link, network socket, or radio channel. On the receiving side, the data is deserialized back into the original structure.
Naive approaches, such as sending raw bytes, often fail when different processors, endianness, or languages are involved. A standardized serialization method ensures compatibility across devices and long-term maintainability.
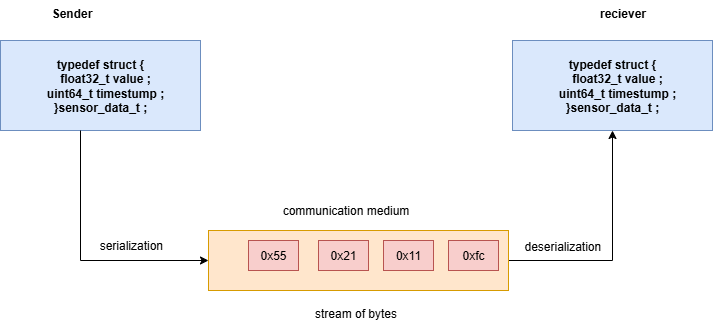
Fig. 1 – Serialization and deserialization.
3. Protobuf and the Embedded Catch:
Protocol Buffers, or Protobuf, is one of the most widely used serialization formats in modern software. It is language-neutral, platform-independent, and comes with mature tooling: define your messages in a .proto file, run the compiler, and get ready-to-use code for C++, Java, Python, or Go. This makes it very attractive for systems that must exchange structured data across platforms.
The challenge arises when you try to bring standard Protobuf into deeply embedded systems. The reference implementation is designed with servers and mobile devices in mind, where dynamic memory allocation and relatively large code footprints are acceptable. On small MCUs with tens of kilobytes of RAM and flash, the heavy runtime, dynamic allocation, and reliance on C++ become significant obstacles. Even if you manage to fit it, performance can suffer because memory allocation and parsing overheads are expensive in real-time environments.
This mismatch is often referred to as the "embedded catch." Protobuf solves the data interchange problem elegantly, but its default implementation is simply too resource-hungry for many microcontrollers. Developers therefore need lighter alternatives that preserve compatibility with the Protobuf ecosystem while respecting the constraints of embedded hardware.
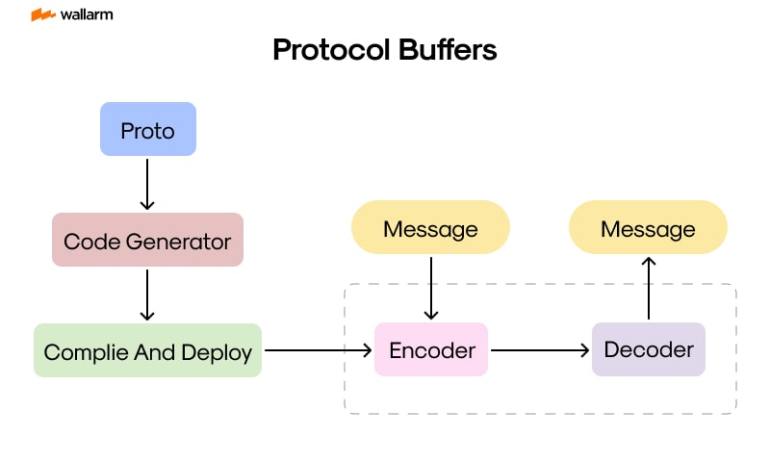
Fig. 2 – Protobuf workflow.
Credit: https://i0.wp.com/lab.wallarm.com/wp-content/uploads/2023/12/253-min.jpg?w=770&ssl=1
4. Embedded-Friendly Options: Nanopb:
One of the most popular solutions for bringing Protobuf into small devices is Nanopb. It is a tiny C library that generates code directly from your .proto files but avoids the heavy runtime of the standard Protobuf implementation. Unlike the full version, Nanopb does not use dynamic memory; instead, everything is handled with static buffers. This makes memory usage predictable and safe, which is critical on MCUs with tight constraints.
The workflow is straightforward. You define your schema in a .proto file, run Nanopb's generator, and include the generated C code in your firmware. On the microcontroller side, you fill the struct, call the encoder to produce a byte stream, and send it over your chosen link. On the host side, the same bytes can be decoded with any standard Protobuf library, ensuring compatibility across platforms.
Nanopb is widely adopted because it strikes the right balance: it is light enough for 32-bit MCUs with only a few kilobytes of RAM, yet still keeps your communication aligned with the broader Protobuf ecosystem. For example, imagine we want to send telemetry data consisting of a timestamp and a sensor reading. We first describe the structure in a .proto file, such as:
message Telemetry {
uint32 timestamp = 1;
float value = 2;
}After running the Nanopb generator, two files are produced (telemetry.pb.c and telemetry.pb.h) that define the C structures and encode/decode functions. In the MCU code, we include these files, fill the Telemetry struct with real values, and use Nanopb's API to serialize and deserialize messages:
/** Encode Telemetry message */
Telemetry msg = Telemetry_init_zero;
msg.timestamp = get_time();
msg.value = read_sensor();
uint8_t buffer[64];
pb_ostream_t stream = pb_ostream_from_buffer(buffer, sizeof(buffer));
if (pb_encode(&stream, Telemetry_fields, &msg)) {
send_uart(buffer, stream.bytes_written);
}
/** Decode Telemetry message */
Telemetry recv_msg = Telemetry_init_zero;
pb_istream_t istream = pb_istream_from_buffer(buffer, stream.bytes_written);
if (pb_decode(&istream, Telemetry_fields, &recv_msg)) {
printf("Time: %u, Value: %f\n", recv_msg.timestamp, recv_msg.value);
}This small example shows the entire workflow: fill the struct, encode it into bytes, transmit it, and decode it back into the same structure on the other side. It keeps communication efficient on the MCU while remaining fully compatible with Protobuf on larger systems.
Another option worth noting is upb, a lightweight C implementation that is now part of the official Protobuf project. It offers efficient parsing and encoding with lower memory usage than the full C++ runtime, making it well-suited for mid-range devices that have more resources than the smallest MCUs but still need lean code. For projects that want closer feature parity with upstream Protobuf while staying embedded-friendly, upb provides a solid alternative.
6. Conclusion:
Serialization is the key to making embedded devices speak the same language as PCs, phones, and cloud systems. While full Protobuf is too heavy for small MCUs, lightweight libraries like Nanopb bring the same benefits with minimal overhead. By defining messages once in a .proto file and sharing them across platforms, developers get reliable, maintainable communication without reinventing protocols.