How Does the CPU Predict the Next Instruction?
1. Introduction
A CPU executes instructions from a program, which is simply a sequence of 0s and 1s in machine code. The CPU uses the Program Counter (PC) to keep track of the address of the next instruction to execute. In most cases, programs follow a sequential flow, but sometimes this flow is interrupted by a branch — for example, when a specific condition is met and the CPU needs to jump to a function or handler. In these cases, the next instruction is no longer at PC + 1, but at a new target address. These control flow changes happen frequently in real programs.
To handle this efficiently, modern CPUs include special hardware blocks called branch predictors. Their job is to guess the outcome of branches before they are actually resolved. This allows the CPU to speculatively fetch and execute instructions, keeping the pipeline full and maintaining high performance.
2. Why Branch Prediction is Needed?
Modern processors use pipelining to boost performance by dividing instruction execution into multiple stages. This allows the CPU to work on several instructions in parallel, with each instruction at a different stage of completion.
However, branches introduce a challenge to pipelining.
In most processors, the branch decision is made during the Execute stage. But by the time the CPU reaches this decision, the Fetch and Decode stages have already loaded the next sequential instructions — because the pipeline doesn’t yet know if the branch will be taken.
If the branch is taken, these prefetched instructions are incorrect and must be discarded. This process is called a pipeline flush.
After flushing, the pipeline must refill with the correct instructions, causing a temporary pause in useful work. The empty slots left during this time are known as pipeline bubble.
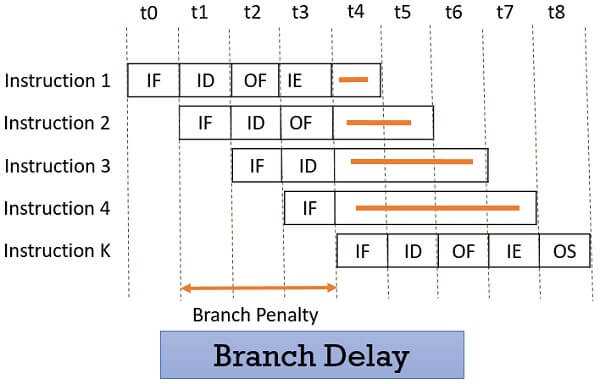
To address this problem, CPUs include a dedicated block called a branch predictor, which tries to determine in advance whether a branch will be taken.
3. Branch Prediction Types on ARM Cortex-M7
3.1 Static Prediction
In static branch prediction, the CPU uses fixed rules to guess the outcome of a branch.
Backward branches:
If the jump is to a lower memory address, the branch is considered taken — this is typically the case in loops.
Forward branches:
Forward branches jump to higher memory addresses and are usually predicted as not taken, like in conditional statements.
3.2 Dynamic Prediction
In dynamic prediction, the CPU uses a learning strategy based on past behavior. It adjusts its predictions over time, similar to how a closed-loop control system operates.
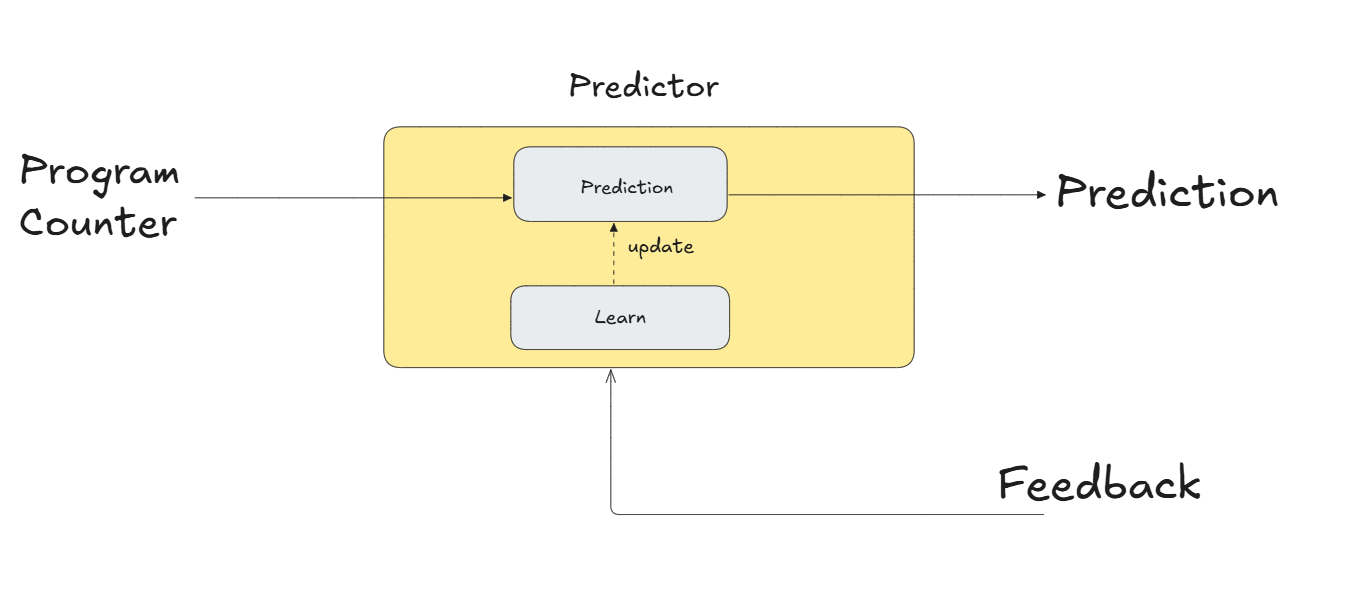
Temporal Correlation
The outcome of a branch in the past is often a good predictor of how it will behave in the future.
For example, if a branch was taken the last few times, it is likely to be taken again.
Spatial Correlation
Sometimes, multiple branches are related. For example, after one branch is taken, nearby branches may follow a specific pattern or path. The CPU can learn these correlations to improve prediction accuracy.
Branch History Table (BHT)
The Branch History Table (BHT) is a mechanism that works like a lookup table to record the past behavior of branch instructions and predict whether a future branch will be taken or not. The BHT uses the lower k bits of the branch instruction’s address (PC) to index into the table. When the CPU decodes an instruction and identifies it as a branch, it checks the corresponding BHT entry to predict the branch direction. After the branch is resolved, the BHT updates the entry to reflect the actual outcome.
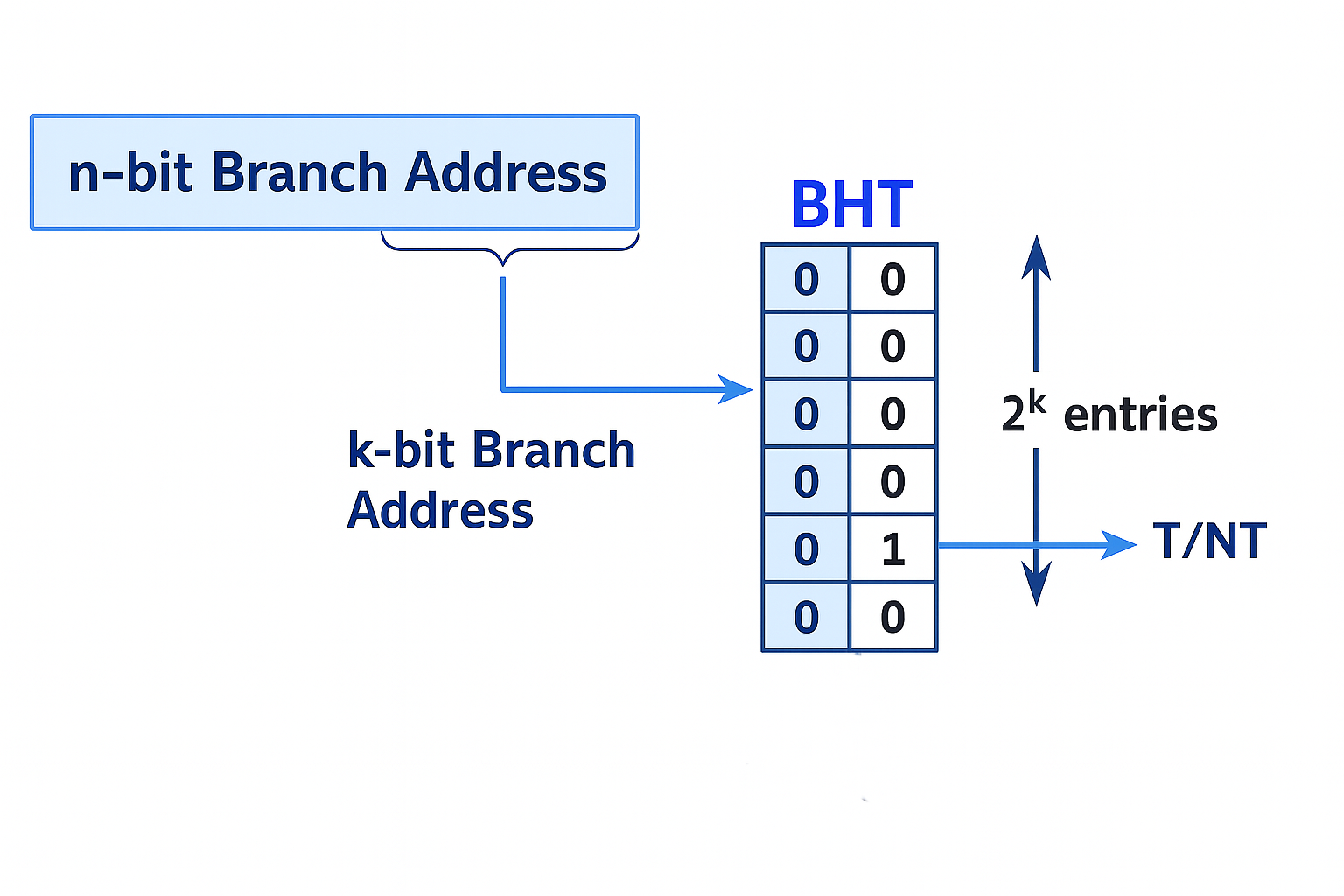
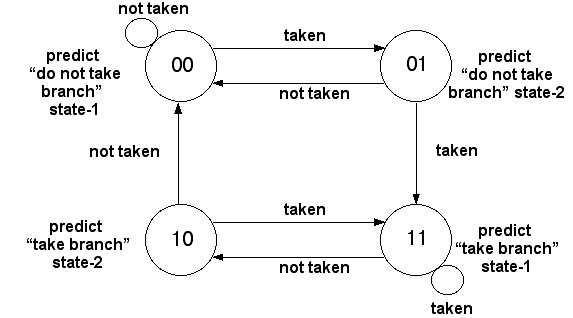
Each BHT entry typically stores a 2-bit saturating counter to manage these updates, allowing the predictor to tolerate occasional mispredictions without changing its behavior too quickly. The direction prediction only changes after two successive incorrect predictions.
Branch Target Buffer (BTB)
Even if the CPU knows that a branch will be taken — thanks to the BHT — it still needs to know where to jump. The Branch Target Buffer (BTB) is a cache-like structure that stores the target addresses of recently taken branches. This allows the CPU to immediately determine the branch destination and start fetching instructions from there, reducing pipeline stalls.
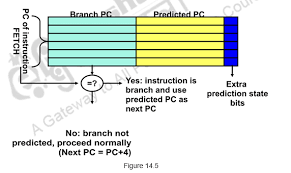
4. Practical Example: Measuring Branch Prediction Impact on Cortex-M7
In this experiment, we measure the performance impact of branch prediction on an ARM Cortex-M7. We compare two scenarios:
Deterministic Branch
A for loop with a condition that is always true (i < threshold). This creates a predictable branch that the branch predictor quickly learns, resulting in minimal pipeline stalls.
void predectible_branch()
{
volatile uint32_t sum = 0;
volatile uint32_t threshold = 500;
volatile uint32_t i = 0U;
for (i = 0; i < 100000; i++)
{
if (i < threshold)
{
sum += i;
}
}
}Unpredictable Branch
A for loop where the condition uses rand() % 2, producing random outcomes. This causes frequent branch mispredictions.
void unpredictable_branch()
{
volatile uint32_t sum = 0U;
volatile uint32_t i = 0U;
for (i = 0; i < 100000; i++)
{
if (rand() % 2)
{
sum += i;
}
}
}We use the Cortex-M7 Data Watchpoint and Trace (DWT->CYCCNT) register to measure the number of cycles taken by each loop.
CoreDebug->DEMCR |= CoreDebug_DEMCR_TRCENA_Msk;
DWT->CYCCNT = 0;
DWT->CTRL |= DWT_CTRL_CYCCNTENA_Msk;
uint32_t cycles_det, cycles_unpred;
DWT->CYCCNT = 0;
predectible_branch();
cycles_det = DWT->CYCCNT;
DWT->CYCCNT = 0;
unpredictable_branch();
cycles_unpred = DWT->CYCCNT;This shows that unpredictable branches are approximately 5× slower due to frequent branch mispredictions.
5.Conclusion:
Branch prediction plays a big role in helping modern CPUs run fast and efficiently, especially in pipelined designs like the ARM Cortex-M7. When your code has predictable branches, the CPU stays ahead and keeps its pipeline full. But when branches become unpredictable, the CPU has to pause and correct itself, which slows things down.
That’s why it’s important—not just for compilers but for developers too—to understand how branch prediction works ant try to Write branch-friendly code is to get better performance.