Threads, Pipes, and Queues: A Beginner’s Guide to Inter-Process Communication
When running an operating system in a system — whether it is a real-time OS or a general-purpose OS (for example, a Linux-style system) — an application is typically divided into multiple tasks, and each task may be divided into threads.
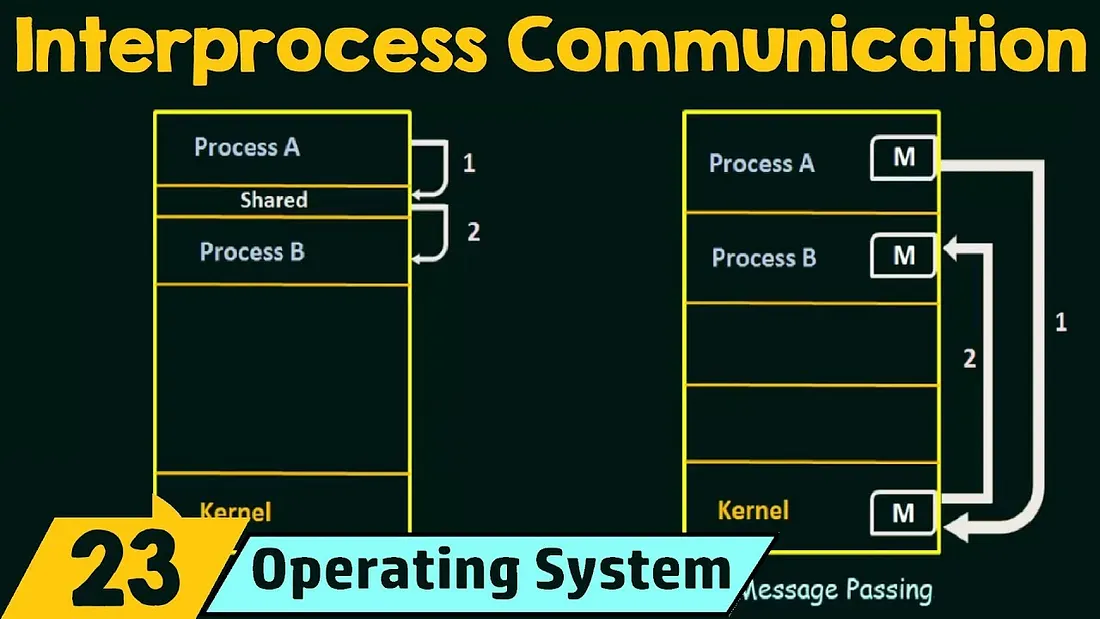
Address space and isolation
In general-purpose operating systems such as Linux, processes execute in logical (virtual) address spaces. Although multiple processes may use the same logical addresses, the CPU and OS map those to separate physical memory, so each process effectively has its own physical address space. This isolation protects processes from accidentally (or maliciously) corrupting each other, but it also makes sharing data between processes more complicated.
Real-time operating systems (RTOS) sometimes run on systems without virtual memory. Even in those cases, it is common to isolate the address spaces of different tasks to improve safety and predictability. That isolation likewise creates a need for explicit mechanisms to share information between tasks.
Threads, by definition, execute within the same process address space and therefore can share memory easily. For threads the usual approach is to allocate a shared region of memory and synchronize access with primitives such as mutexes or semaphores. Inter-process communication (IPC), on the other hand, requires explicit facilities provided by the OS.
Common IPC mechanisms
Below are several widely used IPC mechanisms, with a short explanation, typical properties, and trade-offs.
Pipes
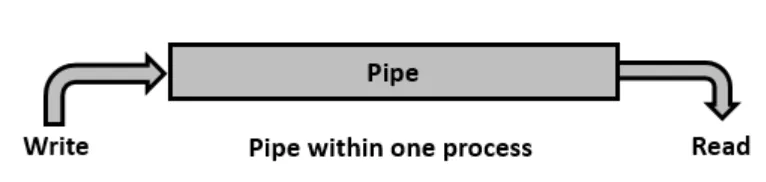
- What it is: A pipe is a stream-oriented communication channel. Data written into one end can be read from the other.
- Usage: Anonymous (unnamed) pipes are typically created between a parent process and its child(ren). Named pipes (FIFOs) can be used by unrelated processes on the same host.
- Semantics: Pipes are generally stream-based (no inherent message boundaries) so communicating processes must agree on framing or delimiters.
- Direction: Unnamed pipes are often unidirectional (simplex); you can create a pair for bidirectional communication.
- Blocking behavior: Writing to a full pipe or reading from an empty pipe can block the process (synchronous), although non-blocking modes are possible.
- Performance: Pipes are efficient for streaming data because they avoid complex control structures, but buffer sizes are implementation-dependent (historically small — e.g., a few kilobytes — but may vary by OS and configuration).
- Limitations: Typically limited to communication on the same host and, for anonymous pipes, limited to parent/child relationships.
Message Queues (Queue)
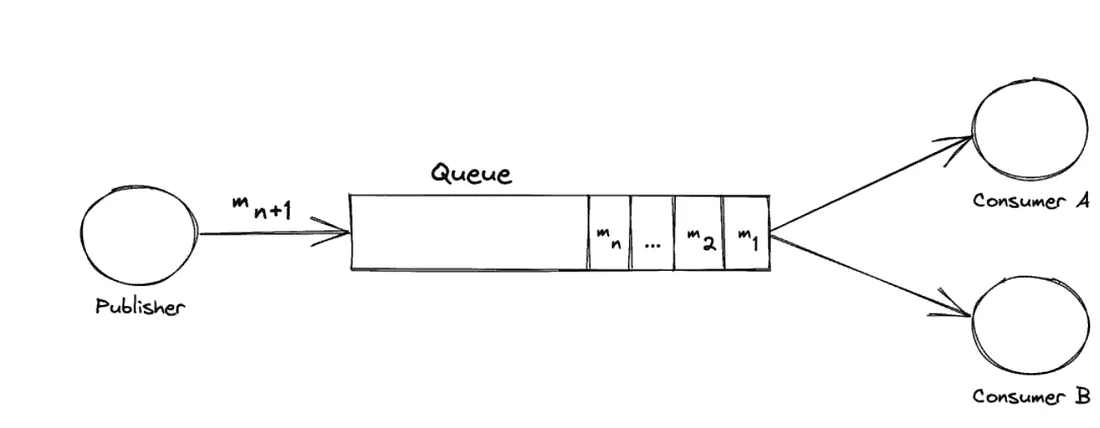
- What it is: A message queue is a kernel-managed data structure where processes post discrete messages and others retrieve them.
- Usage: Message queues allow one-to-many or many-to-many topologies; they can implement publisher/subscriber patterns.
- Semantics: Messages preserve boundaries (each message is an atomic unit). The queue is managed by the kernel, so operations usually involve system calls.
- Blocking vs asynchronous: Sending can be synchronous (blocking until there's space) or asynchronous (enqueue and continue). Receiving can block until a message is available.
- Capacity: Queues may have per-message limits and total capacity; sizes and limits are OS-dependent.
- Pros/cons: Easier to reason about than raw pipes for message-based communication, but system-call overhead can be higher than shared-memory approaches.
Shared Memory
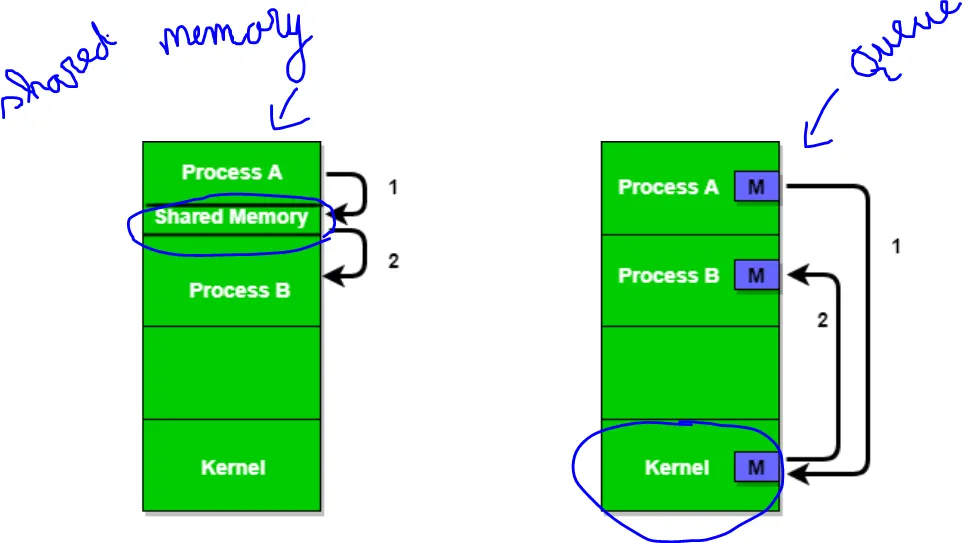
- What it is: A region of memory that multiple processes map into their address spaces so they can read and write directly.
- Usage: The kernel typically sets up the shared mapping, but it does not enforce higher-level synchronization.
- Performance: Shared memory is the most efficient method for large or high-bandwidth transfers because it avoids copying data through kernel buffers and minimizes system calls.
- Synchronization: Producers/consumers must coordinate access using synchronization primitives such as mutexes, semaphores, or condition variables to avoid races and ensure data consistency.
- Trade-offs: Excellent throughput and low latency, but increased complexity due to manual synchronization and safer management requirements.
Mailbox
- What it is: A mailbox is a messaging construct (similar to a message queue) that stores messages for a recipient. The exact meaning of "mailbox" varies across operating systems and RTOS implementations.
- Usage: Processes or threads post messages addressed to a mailbox; consumers retrieve messages as needed.
- Built-in synchronization: Many mailbox implementations provide built-in synchronization primitives (e.g., internal semaphores) to safely manage concurrent access by multiple senders or receivers.
- Pros/cons: Mailboxes simplify concurrent access compared to raw queues because they often include synchronization; however, the built-in protections may introduce more overhead than a carefully-optimized shared-memory solution.
Choosing an IPC method
Which IPC mechanism is best depends on the use case. Consider these criteria:
- Latency: How quickly must the producer hand off the message and continue? Low-latency handoff favors shared memory or lock-free approaches.
- Bandwidth: How much data must be transferred? High-bandwidth transfers favor shared memory; smaller message workloads often suit queues or mailboxes.
- Message semantics and framing: Do you need message boundaries (use message queues or mailboxes) or a byte stream (use pipes)?
- Concurrency model: Will many producers/consumers access the same channel concurrently? Mailboxes or kernel-managed queues with synchronization are often simpler in that case.
- Distribution: Do communicating processes live on the same host? Local IPC mechanisms (pipes, shared memory, queues) work only on the same machine; distributed messaging systems are required for cross-host communication.
- Complexity vs control: Shared memory gives best performance but requires manual synchronization; queues/mailboxes are easier to use but add kernel overhead.
- Reliability and loss tolerance: Consider whether messages can be dropped or must be persisted, and whether ordering guarantees are required.
Conclusion
IPC is a toolbox: there is no single "best" mechanism. Use the mechanism that matches your requirements for latency, throughput, concurrency, complexity, and correctness.
> Note: Buffer sizes, exact semantics, and available IPC primitives vary by operating system and runtime (for example, POSIX APIs, System V IPC, or RTOS-specific APIs). The examples and numbers in this document are illustrative; always check your target system's documentation for precise behavior and limits.